

Why AGI is closer than you think
Let's talk timelines

This post explains why I have short timelines to Artificial General Intelligence (AGI) and you should too.
I plan to get back to my AI and Leviathan series soon, but since its arguments hinge on the trajectory of AI more broadly, explaining why AGI is near seems worth the digression. It’s also relevant to public policy, as the lack of consensus on where AI is headed makes consensus on how governments should respond impossible.
The following points are fleshed out below with many citations and links for further reading. I won't try to wow you with specific AI benchmarks, like the finding that GPT-3.5 spontaneously learned to play above average chess, nor give a specific roadmap for building AGI. Rather, my goal is to explain why you should have strong priors for AGI being near independent of knowing the specifics in advance.1
In bullet form, AGI is near because:
However one defines AGI, we are on the path to brute force human level AI by simply emulating the generator of human generated data, i.e. the human brain.
Information theory, combined with forecasts of algorithmic and hardware efficiency, suggest systems capable of emulating humans on most tasks are plausible this decade and probable within 15 years.
The brain is an existence proof that general intelligence can emerge through a blind, hill-climbing optimization process (Darwinian evolution), while the evidence that the brain works on the same principles as deep learning is overwhelming.
Scale is the primary barrier to AGI, not radically new architectures. Human brains are just bigger chimpanzee brains that achieved generality by scaling the neocortex.
Artificial neural networks can accurately simulate cortical neurons and other brain networks, while the evidence that the brain’s biological substrate matters in other ways is either weak or nothing that bigger models can’t compensate for.
The human brain must work on relatively simple principles, as it grows out of a developmental process with sensitive initial conditions rather than being fully specified in our DNA.
“Universality,” or the observation that artificial neural networks and our brain independently learn similar circuits, is strong evidence that current methods in deep learning are sufficient for modeling human cognition even if they're suboptimal.
We tend to overestimate human intelligence because, as humans, we are computationally bounded in our ability to model and predict other humans.
The number of “hard steps” earth passed through to reach intelligent life suggests the steps aren’t as hard as they look, but are instead guided by statistical processes that mirror the scaling laws and phase-transitions seen in neural networks and other physical systems. AGI isn’t as hard as it looks either.
AGI as a human emulator
AGI is considered tricky to define, as concepts like “generality” and “human-level intelligence” open up bottomless philosophical debates. As such, many prefer the sister concept of Transformative AI – an operational definition that ignores the intrinsic properties of an AI system in favor of its external impact on the economy. An AI system that can automate most human cognitive labor would thus count as TAI even if it was based on something as “dumb” as a giant look-up table. This is somewhat dissatisfying, however, as what makes recent AI progress so exciting is precisely the “spark of general intelligence” seen in models like GPT-4.
Fortunately, the definitions of TAI and AGI converge with AI systems trained to directly emulate human cognition, as an efficient human emulator would be both transformative economically and obviously “human-level” in its generality, even if its exact mechanisms remained opaque. Large Language Models are a step in this direction, as there are good theoretical reasons to think a sufficiently large model for next word prediction trained on human-generated text will learn semantic representations that converge on the representations used by humans.2

While there may be some simple algorithm for general intelligence, the abundance of human-generated data and the exponential growth in computation makes “brute forcing” AGI through human emulation the most likely path forward, and certainly the one the tech industry is optimized for. It may even turn out that “general intelligence” requires models with substantial complexity, as neural networks are known to derive their capacity for generalization and extrapolation from learning on data with a large number of dimensions.
The current ramp-up in computing resources is truly incredible. The global cloud computing market is expected to double over the next four years. The GPU market is growing at a compound annual rate of 32.7 percent off of demand for AI accelerators. As supply-chain bottlenecks alleviate, NVIDIA alone plans to ship 4x more H100s next year than it will ship in 2023. Meanwhile, the compute used to train milestone deep learning models is growing 4.2x per year. At this rate, deep learning would soon consume all the compute in the world. Fortunately, algorithmic progress is doubling effective compute budgets roughly every nine months.
The question “when will we develop AGI” can thus be substituted with the question “when will we have the computing power to faithfully emulate human performance on tasks that require truly general intelligence?” This approach to defining AGI revives the core insight of the original Turing Test, which judged an AI as intelligent to the extent that humans failed to distinguish it from other humans in a series of double-blind conversations. While LLMs have arguably surpassed weaker versions of the Turing Test already, the criterion of indistinguishability remains profoundly useful, especially when formalized mathematically.
The view from information theory
In information theory, minimizing the distinguishability between two distributions is equivalent to minimizing the “cross entropy loss.” Cross entropy is the average number of bits required to tell two data streams apart. Minimizing the cross entropy loss thus means increasing the number of bits needed to distinguish between two distributions. This is the essence of how machine learning models are trained. In a report for EpochAI, Matthew Barnett and Tamay Besiroglu use this fact to build the Direct Approach model, which is perhaps our best information-theoretic forecast of when an AI model will, in principle, be able to emulate human-level performance over long sequences of tasks.
The Direct Approach model combines the AI scaling laws – the empirical fact that model performance increases as a smooth power law with more data, parameters, and training compute – with projected trends in training inputs, such as the availability of computing resources and improvements to hardware and algorithmic efficiency. Along with an estimate of the average number of tokens a human would need to discriminate between human and machine performance, the model yields an upper bound on the training compute required to automate a task at human level. It’s an upper bound because, as the authors explain,
[A]t a certain point, the model might be trained more efficiently by directly getting reward signals about how well it’s performing on the task. This is analogous to how a human learning to play tennis might at first try to emulate the skills of good tennis players, but later on develop their own technique by observing what worked and what didn’t work to win matches.
Benchmarked to the task of generating an original scientific manuscript that’s indistinguishable from one written by an expert human, the baseline Direct Approach model suggests a transformative AI training run will require on the order of 10^32 FLOPs, with a median forecast of TAI by 2036 and a modal forecast of 2029. This comports with the Metacalus forecast of “strong AGI” by 2030.3

What I like about the Direct Approach is that it’s, well… direct. If we can agree that the brain is a physical system with a certain computational capacity, sufficiently powerful computers with sufficiently sample-efficient neural networks should eventually be able to squeeze all the relevant entropy out of human generated data and asymptotically approach an ideal human emulator. The model thus gives a sense of how soon we’ll be able to “brute force” a human emulator given what we know about model scaling and the laws of thermodynamics.
Neural networks are “universal function approximators,” meaning they can approximate arbitrary continuous functions on a compact set. And in case you didn’t know, “everything is a function!” – including the brain. Yet this property only guarantees that a neural network for emulating the brain exists, not that it’s efficient to learn. The Direct Approach model helps bridge this gap by showing that functional approximation of human-level intelligence is not just possible in theory, but should be doable within the next 10 to 15 years.
While there is plenty of uncertainty and room to quibble, this is a fundamentally conservative estimate, as our growing knowledge of the human brain and the interpretability of neural networks means we can do better than brute force. From the use of intermediate forms of AI to speed-up research, to the discovery of tricks that improve scaling behavior, be prepared for many surprises on the upside.
The view from the brain
Using the mathematics of indistinguishability to emulate human intelligence might seem crude, but machine learning engineers do it every day. This can be seen most vividly in the training process for a General Adversarial Network. GANs are trained to discriminate between real and fake data by going head-to-head against a model trained to generate increasingly good fakes – a kind of unsupervised, iterative Turing Test. At some point, the fake data becomes so hard to discriminate from the real data that it’s reasonable to assume the generator model learned the essential features of the real distribution.
GANs are commonly used to generate synthetic images of people that look indistinguishable from real photos. They do this by not merely copy and pasting from the training data, but by discovering circuits for detecting increasingly subtle facial features. New faces can then be generated by composing and interpolating between those features.
Human visual perception is based on deep neural networks that work similarly. The presence of specialized feature detectors in our visual cortex explains why we excel at telling human faces apart, for example, while the faces of non-human animals like sheep all tend to look the same. This also explains why we often see faces where there are none, proving that humans are still vulnerable to adversarial attacks. We just call them optical illusions.
Not enough people seem aware of the progress computational neuroscience has made in just the last decade. The emerging consensus is that the brain simply is a deep reinforcement learning model, albeit one shaped by biological constraints.4 The architectures the brain uses are varied, potentially combining RL models, recurrent and convolutional networks, forms of backpropagation, predictive coding and more. This diversity is a byproduct of evolutionary path dependence and energy constraints. Different types of neural networks are more efficient at different kinds of processing. As a self-organizing system with physical locality, biological neurons differentiate during the brain’s development and form short connections with their neighbors, inducing a modular structure.
The complexity of the brain thus betrays a deeper simplicity, just as the inscrutability of a large neural network betrays the simple algorithms used in training. Indeed, the brain must be based on simple principles, as it “grows itself” through a developmental process rather than being fully specified in our DNA. The haploid genome in humans consists of 2.9 billion base pairs that encode a maximum of 725 megabytes of data. Of this, as little as 8% of our DNA is actually functional, while only 20,000 genes are responsible for all of protein-coding. This makes the genome an absurdly sparse model of the organism it’s used to build. Decompressing our genetic code requires regulating an alphabet soups of proteins into basic cells, setting off a cascade of bioelectrical feedback loops that give rise to nested hierarchies of higher scale forms of structure. Every stage of this process resembles a version of gradient descent, as if genetic mutations tweak a high dimensional “reward function” – a cybernetic attractor – that then steers our embryonic development toward a phenotype corresponding to the lowest energy state.5
Biological evolution is itself a form of gradient descent – hence why Darwin called it “descent with modification.”6 Yet we don’t have to rerun millions of years of natural selection to recreate human-level intelligence. Our brain and its measurable outputs provide a cheat code, letting us leap to language models that have the sort of rich semantic understanding that only evolved once across the nearly 600 million year history of life on earth. AGI forecasts based on evolutionary anchors thus tend to be overly pessimistic. Neural networks excel at modeling other neural networks, and the brain provides a biological artifact for doing just that.
Humans and chimpanzees share 98.8% of their DNA and have brains that are virtually identical in structure. The main difference is that human brains are three times bigger and have an extra beefy neocortex. Our bigger brains are owed to just three different genes thought to have evolved 3 to 4 million years ago. Those fateful mutations took us from being small group primates to a species with such sophisticated problem solving capacities that we eventually went to the moon. Whether or not scale is literally all we need, this is clear evidence that scale is the key ingredient for general intelligence. And since cortical neurons are “well approximated by a deep neural network with 5–8 layers,” we’re on track to being able to build an artificial neocortex many fold bigger than what biology could ever allow.
We tend to overestimate human intelligence because, as humans, we are computationally bounded in our ability to model and predict other humans. The Cartesian legacy in how we conceive of mind and body as irreducibly separate doesn’t help. We’re also simply full of ourselves, as if the notion than an AI could ever be wise, creative or compassionate were a personal affront. This is a mistake – a cognitive illusion rooted in our finiteness as beings embedded in a virtual reality model generated by our waking brains.
In truth, the latest science points to human intelligence being uncomfortably simple. Our decision making even appears to be guided by a unified utility function with as few as two parameters. Contrary to the popular view that humans are “predictably irrational,” cognitive biases like loss aversion and base rate neglect drop right out of an optimal utility function modified for the thermodynamic cost of information processing. Our sense of free will and agency are likewise products of our boundedness, as agentic control systems naturally arise at the Markov boundary of an organism’s ability to deterministically predict future world states. Whether knowing this hurts your self-esteem or inspires wonder in the unity of nature is up to you.
The Universality Hypothesis
By now, there are innumerable examples of neural networks learning specialized neurons and circuits that neuroscientists later discover also exist in the brain. This has led to a rich interplay between neuroscience and machine learning, with new AI models inspired by the brain, and new brain models inspired by AI. Over and over again, the feature detectors learned by artificial neural networks have been found to not merely resemble the networks in the brain, but often share nearly identical mathematical properties – a phenomenon called “universality.”
Examples of universality in the wild can seem mysterious. After all, there are infinitely many ways to represent any given data, and yet models trained using gradient descent independently discover similar representations with striking frequency. The reason relates to the thermodynamics of information. Changing a bit of information takes energy, so reducing the error in a model requires producing some amount of heat – there’s no free lunch. Gradient descent is thus biased towards finding not just any optima, but the most energy efficient representation out of an otherwise enormous landscape. The same is true of the brain, as neuronal plasticity comes at a significant metabolic cost.
The cost-conscious bias in learning algorithms takes the form of a simplicity preference that’s reminiscent of Occam's razor: the most parsimonious explanation is usually the best. These are called inductive biases in machine learning, and they arise due to the logic of Kolmogorov complexity. The Kolmogorov complexity of an output is defined as the length of the shortest program required to produce the output. A long, seemingly random list of numbers has a low Kolmogorov complexity if there’s secretly a short program that generates the list, whereas the shortest program for a list of numbers with maximum Kolmogorov complexity is at least as long as the list itself. Finding expressive representations with low Kolmogorov complexity is thus closely related to efficient data compression, and seems to be the origin of generalization.
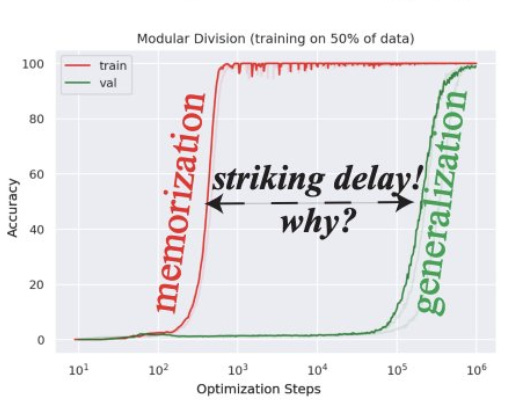
Unfortunately, Kolmogorov complexity is not computable. Finding low complexity programs thus requires brute search, which manifests in machine learning as “grokking.” Grokking is when a machine learning model rapidly reaches zero training error by overfitting its parameters (i.e. memorizing the data), only to exhibit a sudden phase change in generalization ability when training is allowed to run for longer. This happens because memorization is easy, while finding the “shortest program” that generalizes the data is hard. By letting the network weights decay as you continue to train the model, gradient descent eventually probes the unlikely paths to a lower complexity data compression, like finding a needle in a high dimensional haystack.7 The existence of the needle is further guaranteed by the “blessing of dimensionality,” which makes getting stuck in a true local optima exceedingly improbable.
Neural networks and the brain are compression machines. At some point, the best way to compress a stream of data is to model the system that generated it. In the limit, the “shortest program” a neural network can find to reliably reproduce feature rich, human generated data will thus approximate the very programs the brain used to generate the data in the first place. If a shorter program existed, evolution would have found it and saved the brain some energy.
This is just scratching the surface. To really understand the origins of universality would require a long detour through statistical mechanics, topology and representation theory. For the purposes of this post, it suffices to know that there are very good reasons to believe that artificial neural networks aren’t merely capable of learning how the human brain represents information, but that human-like representations are often virtually inevitable.
The fact that human life exists at all is itself a testament to universality. From the big bang to the first transistor, getting to our advanced civilization required passing through a long series of “hard steps.” This included having a habitable planet replete with complex organic molecules; the abiogenesis of the first chemical replicators; the evolution of multicellularity, sexual reproduction, and the nervous system; the oxygenation of earth’s atmosphere; the emergence of warm blooded animals with complex social lives; the settlement of early human societies; the agricultural revolution and beyond. Each of these steps was deeply improbable, but with trillions of planets and billions of years to work with, they were also inevitable.

We can infer that intelligent life is easy to create from the fact that life on earth is exceptionally early in the history of the universe. For life to begin at all, the universe had to cool down, form stars, create heavy elements through supernovae, and settle into galaxies and solar systems without too much radiation. The universe is expected to only get more habitable going forward as it continues to cool, leaving many life-supporting planets orbiting dwarf stars for trillions of years. Taking all of this into consideration, life on earth emerged almost as soon as life in the universe could realistically emerge anywhere. This provides a simple solution to the Fermi Paradox: the reason the universe isn’t littered with evidence of alien civilizations is because we’re still in the first cohort.
In short, intelligent life is inevitable because, with enough blind search and variation, nature eventually stumbles on rare, self-reinforcing processes for extracting entropy from the environment. This leads to take-off dynamics that pull nature into a new regime where the search for the next hard step begins anew. Thus, from the Cambrian explosion to the printing press to grokking, ours is a universe that makes hard things easy thanks to the universality of scaling laws and phase transitions.
With AGI around the corner, human civilization is about to go through another such transition – what Carl Shulman and others call the “intelligence explosion.” If this still sounds improbable to you, it’s because it is. And yet nature finds a way.
I’m agnostic on whether specific approaches to AI, like autoregressive transformer models, will get us all the way to AGI. I’m confident that they can, as transformers are universal function approximators, but whether that’s the most efficient, long-run approach remains to be seen. More likely than not, I suspect AGI-level models will have a mixed architecture that combines the strengths and weaknesses of different model types. We’re already seeing versions of this through “mixture of expert” models, systems that use transformers as a semantic kernel, and in models that combine self-attention with reinforcement learning. That said, while “no free lunch theorems” are pessimistic about a single AI model that can do everything, these theorems rest on fragile assumptions that easily breakdown, suggesting a single learning algorithm may be indeed be “all we need.” The key point is to not let your 10 year forecast get too distracted by these near-term details, and to instead focus on what can be safely extrapolated from the universal properties of deep learning at scale per se. Whether or not scale is sufficient, it’s clearly necessary and by far the hardest step, as finding the best way to harness that scale reduces to an engineering and search problem with finite depth.
Note, I am not saying we need or should even want a 1 to 1 emulation of the human brain. Rather, we merely need a lossy compression of the intelligence latent in human data, and one that gets predictably less lossy with scale. Most of what the brain does isn’t relevant to AGI. Why emulate the part of the brain that controls digestion, say? We just need to simulate the models the brain uses for abstract thinking, creativity, reasoning, context awareness, etc. That's what LLMs are. We don't need granular brain scans. Language data itself contains significant latent information about the way language gets represented in the brain. If LLMs seem a bit alien, it’s because they're a superposition of lots of different kinds of language data produced by lots of different brains.
Note AGI is not the same thing as Artificial Superintelligence. Human-level AIs will be automatically super human in many respects, but not arbitrarily so. The same information-theoretic arguments that make near-term AGI plausible also put bounds on the plausibility of a runaway superintelligence, as a system with a given compute budget can only extract so much entropy from its training data and environment. That doesn’t make a “god-like” superintelligence impossible, but it does mean that we won’t get the true singularity until the requisite computing infrastructure is online, perhaps sometime in the 2040s.
Scientists recently grew a live, biological neural network in the lab using a culture of in vitro human cortical cells. They then connected it to a virtual environment and it learned to play the game Pong. Networks of cortical neurons thus appear to work just like an artificial neural network designed to spontaneously reduce the prediction error of its sensory-action feedback model of whatever environment it happens to be plugged into.
The key takeaway here is that our genetics aren’t a blueprint but rather the first input into a multi-level developmental process that’s guided by cybernetic attractors. This ensures our development is robust to perturbations and greatly simplifies the fitness landscape that evolution searches over. Thus, if an embryo spontaneously splits in two, it will grow into two perfectly well formed monozygotic twins. We’re similarly protected from a useful genetic mutation inadvertently giving us eyeballs on our elbows, as our morphological development is guided by attractors that are hard to knock off course, and thus in some sense shielded from natural selection. For a great overview of this, see Michael Levin’s recent talk on “Emergent Selves and Unconventional Intelligences.” The relevance to this post is that you don’t need to understand every step of an insanely complex process to reproduce it. Provided it’s based on simple principle, you just need the right initial conditions and sets of constraints to let the process unfold itself by rolling down an energy gradient.
I’m using the term “gradient descent” to loosely refer to any optimization algorithm that randomly searches a fitness landscape to find gradual improvements. If anything, natural selection is a dumber learning algorithm than the form of gradient descent used in machine learning, as gradient descent looks for the steepest improvement while evolution just selects for any mutation that improves the inclusive fitness of a single organism. Machine learning models also have a fixed loss function, whereas the definition of “fitness” in the evolutionary context is a moving target that changes with the environment.
To be precise, models seem to memorize the data first and then slowly build the circuits needed for generalization. The “grokking” phase change only occurs once the subnetworks for generalization are in place, letting it suddenly “prune” all the parameters it had been wasting on memorization. In other words, “grokking corresponds to sparsification.”
This is a really compelling synthesis of interdisciplinary ideas. Like Jason though, I think using evolution as a precedent is tricky and nuanced. Evolution operates on large populations while AI training is repeatedly performed on a single "individual". The claim that both processes are at heart the same form of optimization is a type of ergodic hypothesis* - perhaps this is true but it is not self evidently so.
* https://en.wikipedia.org/wiki/Ergodic_hypothesis
Amazing post, thanks for pulling all those links together into a coherent whole.